2025

Comprehensive Multimodal Retrieval and Generation System
Zhiran Zhang
Undergraduate Thesis
Developed an end-to-end platform integrating text-to-image generation (VQ-VAE + diffusion), image captioning (CLIP + GPT-2), and text-to-image retrieval (CLIP + Faiss). Achieved high-fidelity synthesis, improved caption accuracy via joint fine-tuning, and sub-second large-scale retrieval, all deployed in a Gradio web UI.
Comprehensive Multimodal Retrieval and Generation System
Zhiran Zhang
Undergraduate Thesis
Developed an end-to-end platform integrating text-to-image generation (VQ-VAE + diffusion), image captioning (CLIP + GPT-2), and text-to-image retrieval (CLIP + Faiss). Achieved high-fidelity synthesis, improved caption accuracy via joint fine-tuning, and sub-second large-scale retrieval, all deployed in a Gradio web UI.
Research on Deepfake Video Generation Technology Based on Deep Learning
Zhiran Zhang, Zhizhuo Liang
Chinese National University Innovation Program
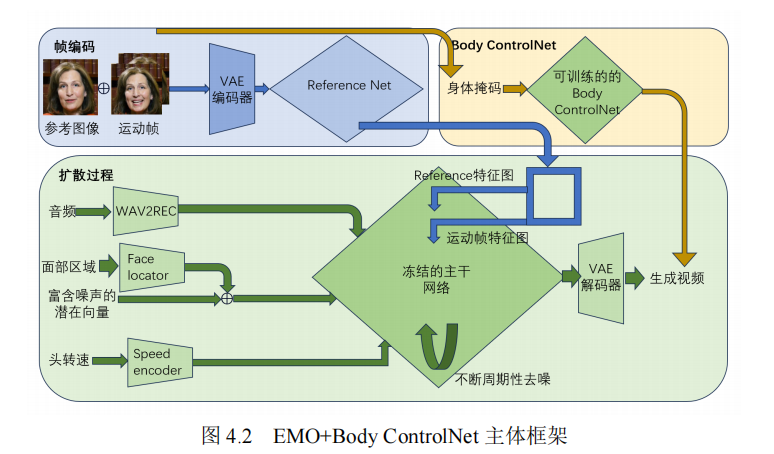
To address the lip-sync limitations of the 3D Gaussian Splatting-based GaussianTalker, we designed a pre-trained synchronization discriminator-driven loss function , achieving improvements of 39.8% in SyncNet scores for French and 23.6% for Chinese scenarios.And combined with the GPT-SoVITS timbre conversion module, the driving audio timbre under the cross-drive setting is consistent with the original timbre. For the non-facial artifact issue in the diffusion-based EMO framework, we proposed a ControlNet-enhanced body-part control branch, which elevates the IoU score for non-facial regions by 18.5% through multi-channel mask fusion and segmentation consistency constraints.
Research on Deepfake Video Generation Technology Based on Deep Learning
Zhiran Zhang, Zhizhuo Liang
Chinese National University Innovation Program
To address the lip-sync limitations of the 3D Gaussian Splatting-based GaussianTalker, we designed a pre-trained synchronization discriminator-driven loss function , achieving improvements of 39.8% in SyncNet scores for French and 23.6% for Chinese scenarios.And combined with the GPT-SoVITS timbre conversion module, the driving audio timbre under the cross-drive setting is consistent with the original timbre. For the non-facial artifact issue in the diffusion-based EMO framework, we proposed a ControlNet-enhanced body-part control branch, which elevates the IoU score for non-facial regions by 18.5% through multi-channel mask fusion and segmentation consistency constraints.
2023

Bike ReID
Haoming Luo, Tian Xie, Zhiran Zhang
Yuqing Cup 2023
Adopted the YOLOx and ReID algorithms to develop a novel AI model that learns bike-person pairs in real-time surveillance scenarios. Input of a bike picture returns its recent locations and warning is sent if abnormal pairing is detected within only 0.24s, making it ideal to alert user if their bike is stolen. Achieved an accuracy of 74% after training with less than 3,000 images.
Bike ReID
Haoming Luo, Tian Xie, Zhiran Zhang
Yuqing Cup 2023
Adopted the YOLOx and ReID algorithms to develop a novel AI model that learns bike-person pairs in real-time surveillance scenarios. Input of a bike picture returns its recent locations and warning is sent if abnormal pairing is detected within only 0.24s, making it ideal to alert user if their bike is stolen. Achieved an accuracy of 74% after training with less than 3,000 images.